논문명 : Attnention is All You Need
저자 : Vasawani et al.
출간지/발간일 : NIPS 2017
한참 전에 읽어두었던 논문이지만 귀찮아서 미루고 미루다... 최근에 좋은 기회가 생겨 다시 읽게되어 세세하게 정리하며 포스팅을 해본다. 이 논문은 현재 NLP, CV등 다양한 분야에서 활용되고 있는 Transformer 구조의 시작이 되는 논문으로, 딥러닝을 공부하는 사람이라면 반드시 한 번은 읽어봐야할 랜드마크같은 논문이다. 처음 공부하는 자세로 하나하나 이해할 수 있도록 열심히 정리를 해보았다..!
I. Introduction
⚠️ 기존 모델의 한계 ⚠️
- 당시 NLP에서 SOTA를 기록하던 모델은 RNN, LSTM, GRU와 같은 순환 신경망 기반 모델들이었음
[순환 신경망] 입력 데이터를 문장의 토큰(단어) 순서대로 처리하는 방식으로, 이전 시간의 정보와 현재 입력을 사용하여 현재 시간의 단어 정보를 계산하는 방식임

- RNN의 한계
RNN의 가장 큰 특징은 입력을 한 번에 처리하는 것이 아닌 한 단어씩 순차적으로 처리해야 하는 것임
따라서, 위의 특징으로 인해 아래와 같은 한계점을 확인할 수 있음
- 병렬 처리 불가능 : 문장의 길이가 길어지면 학습 시간이 오래 걸리고 GPU 활용도가 낮아짐
- Long-Term Dependency Problem : 순차적 특성으로 인해 문장의 앞쪽 정보가 뒤쪽에 잘 전달되지 않는 문제 발생
- 메모리 사용량 제한 : 순차적 특성으로 인해 한 번에 여러 문장을 처리하는 Batch 단위 처리에 제한
Attention mechanism의 등장
- Attention이란?) 입력 시퀀스의 모든 위치를 고려하여 중요한 부분에 집중하는 기법
→ RNN과 달리 입력 문장의 모든 단어를 동시에 고려하여 출력 단어를 생성할 수 있음
→ 기존에는 RNN과 함께 사용되는 경우가 많았음
✅ 논문의 제안 모델 : Transformer ✅
기존 RNN의 순차적인 처리 방식을 완전히 제거하고, 오직 Attention 메커니즘만을 사용하여 시퀀스를 처리하는 모델
A. 병렬 연산 가능
B. Attention 메커니즘을 통한 Long-Term Dependency Problem 해결
C. 학습 속도 개선
II. Model Architecture
본 논문에서 제시하는 Transformer 아키텍처는 다음과 같이 구성되어있다.

모델 구조에서 중요한 부분을 살펴보도록 하겠다.
1️⃣Embedding & Positional Encoding
- Embedding
임베딩이란, Input에 입력된 데이터를 컴퓨터가 이해할 수 있도록 행렬 값으로 바꾸어주는 과정이다.

- Positional Encoding
Transformer는 RNN과 달리 단어 순서대로 넣는게 아닌 문장의 토큰을 한 번에 넣어서 처리한다.
따라서, 단어 간의 순서를 계산하는 과정이 필요함!
→ 순서를 부여하는 방법으로 아래와 같이 삼각함수를 사용하게 되는데, 그렇다면 왜 삼각함수를 사용하는지에 대해 생각해볼 필요가 있다.

[ 순서 정보를 인식하기 위한 방법 ]
임베딩한 값에 순서 정보를 넣기 위한 방법으로 여러 가지를 생각해볼 수 있다.
1. 타임스텝 0~1 사이의 숫자를 부여한다.
- 이는 input의 총 크기를 알 수 없으므로, delta값(단어 간 차이)이 일정한 의미를 갖지 않는다.
ex) 문장의 첫번째 단어 0, ..., 마지막 단어 1
2. 각 타입스텝에 선형적으로 숫자를 부여한다.
- 이는 delta값을 일정하게 설정할 수 있으나, 긴 문장의 경우 값이 매우 커질 수 있으며 모델의 일반화를 저해한다.
ex) 문장의 첫번째 단어 1, 두번째 단어 2, ...
따라서, 다음과 같은 기준을 설계할 수 있다.
a. 각 타임스텝(문장에서의 단어 위치)마다 고유한 인코딩이 출력되어야 함
b. 타임스텝 간의 거리가 길이에 따라 달라져야 함
c. 긴 문장을 일반화시키는 것에 추가적인 cost가 들어가지 않아야 함
d. deterministic 해야함(한 계산에 대해 유일하게 하나의 값만을 갖는 개념)
이 조건을 성립시키는 삼각함수(-1과 1사이를 연속적으로 접근)를 사용한 것이다.
2️⃣ Attention
본 구조에서는 총 3곳에서 Attention 연산이 사용되며, Scaled-dot Attention 연산이 Multi-head로 구성이 되어있다.

[Scaled Dot-Product Attention]
#1. Transformer의 핵심 연산 중 하나로, Attn 메커니즘의 한 유형이다.
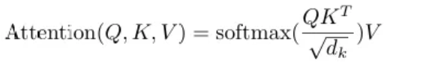
#2. Query, Key, Value를 사용하여 중요도를 계산한 후, 출력값을 생성하는 방식이다.
| Q(Query) | 입력 시퀀스에서 관련된 부분을 찾으려고 하는 정보 벡터 = source |
| K(Key) | 관계의 연관도를 결정하기 위해 Q와 비교하는데 사용되는 벡터 = target |
| V(Value) | 특정 K에 해당하는 입력 시퀀스의 정보로 가중치를 구하는데 사용되는 벡터 |
#3. 연산 과정

현재 입력 토큰과 다른 토큰들의 비교를 통해 Attention Score를 구한다. 이 방식은 Query와 Key의 내적을 통해 이루어진다.


Attention Score를 생성한 후, 두 가지 작업을 진행한다.
i) Scaling : dot-product는 계산 특성상 문장의 길이가 길어질 수록 더 큰 숫자를 가지게 된다. Softmax를 씌우면 특정값만 과도하게 살아남고 나머지 값들은 사라지는 과한 정제가 발생하기 때문에 제곱근 Key 벡터의 차원으로 나누어 스케일링을 진행한다.
ii) Softmax : Attention Score의 유사도를 0~1 사이 값으로 normalize 해준다.

Value와 곱해주면 attention value를 얻을 수 있다.
[Multi-head Attention]
최종적으로는 위의 설명된 Scaled dot Attention을 병렬로 h번 학습시키는 MHA구조를 사용한다.
이 구조를 사용하는 이유는 여러 부분을 동시에 어텐션을 가함으로써 모델이 입력 토큰 간의 다양한 유형의 종속성을 포착하고 다양한 소스의 정보를 결합할 수 있기 때문이다.

- 이 때, h번 곱하는 거면 그만큼 cost가 더 발생할 수 있지 않나? 라는 생각이 들 수도 있다.
그러나, 기존 차원을 h로 나눈 값으로 연산을 하는 것이기 때문에 결국 동일한 연산 시간을 소모하게 된다.

#4. Attention의 여러가지 형태
- Transformer에서 사용되는 3가지의 어텐션은 각자 다른 역할을 한다.
| Encoder의 MHA | - 설명된 MHA 구조와 동일하다 - 입력 문장 내에서 단어들끼리 문맥을 파악하며, 문장 내 모든 단어가 서로를 참조할 수 있다 |
| Decoder의 Masked MHA |
- 기존 MHA 구조에서 Masking을 적용한 형태이다 - Masking 적용 이유 : Transformer가 다음 단어를 예측할 때 아직 생성되지 않은 단어를 보면 안되기 때문에 마스킹을 적용한다. 현재 토큰을 기준으로 이후의 토큰들은 0처리를 한다 |
| Decoder의 Enc-Dec MHA |
- Encoder에서 나온 정보를 Decoder의 Key와 Value로 넣어서 문장을 생성한다 |

3️⃣ Feed Forward
다음으로는 Feed Forward module에 대한 내용이다.
이 module은 input으로 들어온 값을 확장하고 ReLU 함수를 거치게 한 뒤 다시 축소시켜 output으로 내보낸다.
해당 과정을 통해 Attn에서 학습한 정보를 더욱 강화하고, 모델의 비선형성 특징을 뽑아낼 수 있다.

4️⃣ Add&Norm과 Linear&Softmax

III. Comparison
Self Attention과 그 외의 다른 모델 구조(Recurrent and Convolutional Layer)를 비교하는 부분이다.
논문에서는 비교 기준을 다음과 같이 설계하였다.
- 총 연산 복잡도 (Total Computational Complexity per Layer) : 각 레이어의 연산량을 비교하여 효율성 평가
- 병렬화 가능성 (Parallelizability) : 연산을 병렬화 할 수 있는 정도를 측정하기 위해 최소한으로 필요한 순차 연산의 개수를 고려함
- 장기 의존성 학습 능력 (Path Length for Long-Range Dependencies) : 연산을 병렬화할 수 있는 정도를 측정하기 위해 최소한으로 필요한 순차 연산의 개수를 고려
다음으로는 위의 비교 기준에 따른 실험 결과이다.
| Self-Attn | RNN | CNN | |
| 총 연산 복잡도 | O(n^2*d) | O(n^2*d) | O(k*n*d^2) |
| 병렬화 가능성 | O(1) | O(n) | O(log(n)) |
| 장기의존성 학습능력 | O(1) | O(n) | (n/k) - 연속적인 CNN O(log(n)) - Dilated CNN |
→ 병렬화 가능성과 장기의존성 학습능력 측면에서는 Self-Attn이 RNN이나 CNN에 비해 월등히 우수함을 확인할 수 있다. 그러나, 연산 복잡도 측면에서는 다른 모델들과 유사하게 문장의 길이에 영향을 받는다는 것을 확인할 수 있다.
IV. Experiments
본 논문에서 진행하는 실험에 대하여 Traning 정보는 다음과 같다.

- Experiment1. BLEU 점수 및 FLOPs 기반 성능 비교
본 실험을 통해 Transformer 모델이 이전 SOTA 모델보다 더 높은 BLEU 점수를 기록하면서도 학습 비용이 훨씬 적음을 보여준다.

- Experiment2. Model Vatiations
Transformer의 구조에서 몇 가지 요소들을 변경한 후 Englisth-German translation task에 적용한 실험 결과이다.

- Experiment3. English Constituency Parsing
Transformer model이 영어 구성 구문 분석에서 기존 모델과 비교하였을 떄 얼마나 잘 일반화를 하는지 평과한 결과이다.

V. Conclusion
본 연구에서는 Transformer를 소개하였으며, 이는 완전히 어텐션 기반의 첫번째 시퀀스 변환 모델로 기존 인코더-디코더 구조에서 널리 사용되던 순환 신경망을 대체하였다. 향후 연구 방향으로 어텐션 기반 모델의 가능성에 주목하며, 이를 텍스트 이외의 다양한 문제에도 적용할 계획임을 밝혔다.
[내용 도움 및 그림참고]
[1] https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding
[2] https://www.blossominkyung.com/deeplearning/transformer-mha
[3] https://jaylala.tistory.com/entry/개념정리-멀티헤드-셀프-어텐션Multi-Head-Self-Attention



