논문 리뷰 - Efficient Processing of Deep Neural Networks
이 논문은 효율적인 DNN 처리 분야의 최근 발전에 대한 포괄적인 자습서 및 설문 조사를 제공하는 것을 목표로 한다. DNN에 대한 개요, DNN을 지원하는 다양한 하드웨어 플랫폼 및 아키텍처, 하드웨어 및 알고리즘 최적화를 통해 계산 비용을 줄이는 전략 등의 다양한 주제를 다룬다.
1. Introduction
I. INTRODUCTION
II. BACKGROUND ON DNNS : DNN의 역사와 진행도
III. OVERVIEW OF DNNS : DNN의 주요 요소와 주요 모델들
IV. DNN DEVELOPMENT RESOURCES : DNN에 사용되는 다양한 resources
V. HARDWARE FOR DNN PROCESSING : hardware platforms와 다양한 optimizations들에 대한 소개
VI. NEAR-DATA PROCESSING : mixed-signal circuits와 new memory technology가 가지는 의미
VII. CODESIGN OF DNN MODELS AND HARDWARE : joint algorithm과 hardware optimization의 역할
VIII. BENCHMARKING METRICS FOR DNN EVALUATION AND COMPARISON : 다양한 DNN design에서의 비교
2. Background On DNNS
이 절에서는 DNN의 개념과 발전 단계, 적용되고 있는 분야들에 대해서 다룬다.
A. Artifical Intelligence and DNNS
DNN은 딥러닝의 일종으로 AI의 광범위한 분야 중 일부이다. 딥러닝이 전체 인공지능에서 차지하는 위치는 그림1에 나와있다.
AI 안에는 기계학습이라는 큰 하위 분야가 하나 있다. 이는 1959년 Arthur Samuel에 의해 명시적으로 프로그래밍되지 않고도 컴퓨터가 학습할 수 있는 능력을 부여하는 연구 분야로 정의되어 있다. 즉, 각 개별 문제를 해결하기 위해 독특한 맞춤형 프로그램을 만드는 고된 접근 방식 대신, 단일 기계 학습 알고리즘 훈련으로 통해 각 새로운 문제를 처리하는 법을 배우기만 하면 된다는 의미이다.

B. Neural Networks and DNNs
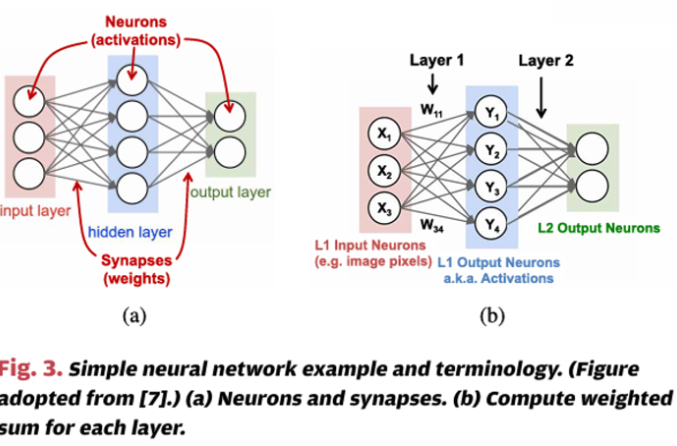
신경망은 뉴런의 계산이 입력 값의 가중합을 포함한다는 개념에서 영감을 받았다. 이러한 가중합은 시냅스에 의해 수행되는 값의 스케일링과 뉴런 내에서 이러한 값을 결합하는 것에 해당한다. 그림 3(a)는 계산 신경망의 그림이다. input layer, hidden layer, output layer 순으로 각각의 값을 전달하며, 이 글로부터 뉴런을 activation, 시냅스를 가중치라고 부른다. 그림 3(b)는 각 층에서의 계산 예를 보여준다. 딥러닝은 신경망이 세 개 이상의 층을 가지며, 하나 이상의 은닉층을 포함한다. 일반적으로 딥러닝에 사용되는 신경망을 지칭하기 위해서는 심층 신경망(DNN)이라는 용어를 사용한다.
C. Inference Versus Training
딥 뉴럴 네트워크(DNN)는 주어진 작업을 수행하는 방법을 학습하는 기계 학습 알고리즘이다. DNN의 학습 과정은 네트워크의 가중치와 바이어스 값을 결정하는 것으로, 이를 훈련(training)이라고 한다. 훈련된 네트워크는 이 가중치를 사용하여 주어진 입력에 대한 출력을 계산하며, 이를 추론(inference)이라고 부른다.
훈련의 목표는 올바른 클래스의 점수를 최대화하고 잘못된 클래스의 점수를 최소화하는 가중치를 찾는 것이다. 손실(loss)은 이상적인 점수와 현재 가중치로 계산한 점수 사이의 차이로, 훈련의 목적은 평균 손실을 최소화하는 가중치 세트를 찾는 것이다. 경사 하강법(gradient descent)은 손실의 기울기를 이용해 가중치를 업데이트하는 방법이며, 역전파(backpropagation)는 기울기를 효율적으로 계산하는 과정이다.
DNN 훈련에는 지도 학습(supervised learning), 비지도 학습(unsupervised learning), 반지도 학습(semi-supervised learning), 강화 학습(reinforcement learning) 등이 있다. 미세 조정(fine-tuning)은 이전에 훈련된 가중치를 새로운 데이터 세트나 제약 조건에 맞게 조정하는 방법이다.
DNN 추론은 자원이 제한된 환경에서 효율적으로 수행되어야 하며, 훈련된 네트워크를 사용하여 주어진 작업을 수행한다.
D. Development History
아래와 같은 timeline처럼 DNN의 발전이 이루어지고 있고, ImageNet 대회의 최고 성능을 통해 초기 정확도로부터 지속적인 개선 성과를 확인할 수 있다.

3. Overview Of DNNs
DNN은 애플리케이션에 따라 다양한 형태와 크기로 제공되며, 정확성과 효율성을 향상시키기 위해 빠르게 진화하고 있다. DNN의 입력은 이미지 픽셀, 오디오 파형의 샘플링된 진폭, 또는 시스템이나 게임의 상태를 수치로 표현한 값들이다.
네트워크는 feedforward와 recurrent 두 가지 주요 형태로 제공된다. feedforward는 입력에 대한 출력이 항상 동일하며, 네트워크에 메모리가 없다. 반면, RNN은 내부 메모리를 가지고 있어 이전 입력의 영향을 반영할 수 있으며, 장기메모리(LSTM) 네트워크가 대표적이다. 이 글에서는 주로 feedforward 네트워크에 초점을 맞춘다.
DNN은 완전 연결(FC)층으로만(a) 구성될 수 있으며, 이는 많은 저장 공간과 계산을 필요로 한다. 하지만 일부 연결을 제거하여(b) 희소 연결 층을 만들 수 있으며, 이는 계산 효율성을 높인다. 또한, 각 출력이 고정 크기 창의 입력만을 사용하거나, 동일한 가중치를 반복 사용하는 경우 효율성이 더욱 향상된다. 이와 같은 구조는 컨볼루션 연산을 통해 구현되며, 이는 작은 이웃만을 사용하여 가중치 합을 계산하고 동일한 가중치를 모든 출력에 공유하는 방식이다.
A. Convolution Neural Networks (CNN)
DNN의 일반적인 형태는 CNN(Convolutional Neural Networks, 합성곱 신경망)이다. CNN은 다수의 컨볼루션 층으로 구성되며, 각 층은 입력 데이터를 점진적으로 더 높은 수준의 추상화된 정보로 변환하는 기능을 수행한다. CNN은 이미지 이해, 음성 인식, 게임 플레이, 로봇 공학 등 다양한 응용 분야에 널리 사용된다. CONV 층은 고차원 합성곱으로 주로 구성된다. 각 층의 입력 활성화 값을 2D 입력 피처 맵으로 구성되며, 각 채널은 서로 다른 2D 필터와 합성곱된다. 필터 결과는 모든 채널에서 합산되며, 1D 바이어스가 필터링 결과에 추가될 수 있다. 필터 결과는 출력 피처 맵(ofmaps)을 형성하며, 추가 3D 필터를 사용하여 더 많은 출력 채널을 생성할 수 있다. 또한, 여러 입력 피처 맵을 배치로 처리하여 필터 가중치의 재사용을 개선할 수 있다.
비선형성, 풀링, 정규화와 같은 다양한 선택적 층도 DNN에서 사용될 수 있다. 비선형성 층에서는 주로 ReLU와 같은 비선형 활성화 함수가 적용되며, 풀링 층에서는 피처 맵의 차원을 줄이는 다양한 계산이 수행된다. 정규화 층에서는 배치 정규화(BN)를 통해 입력 분포를 조절하여 훈련 속도와 정확성을 향상시킬 수 있다. BN은 주로 CONV 또는 FC 층과 비선형 함수 사이에 수행된다.

B. Popular DNN Models
많은 DNN 모델들이 개발되어왔다. 각 모델은 레이어 수, 레이어 유형, 레이어 형태(filter, chanel) 및 레이어 간 연결 측면에서 서로 다른 네트워크 아키텍처를 가지고 있다. 이 섹션은 ImageNet Challenge에서 경쟁/우승한 다양한 DNN을 다룬다. 이러한 모델들은 아래 표로 정리가 되어있다.

4. DNN Development resources
딥 뉴럴 네트워크(DNN)의 급속한 발전은 연구 커뮤니티와 산업계에서 제공한 다양한 개발 자원 덕분이다. 이러한 자원은 DNN 가속기를 개발하고, 워크로드 특성을 제공하며, 모델 복잡성과 정확성 간의 트레이드오프를 탐색하는 데도 중요한 역할을 한다. 이 섹션에서는 이러한 자원을 간단하게 설명한다.
프레임워크
DNN 개발을 용이하게 하고 훈련된 모델을 공유할 수 있도록 여러 딥러닝 프레임워크가 개발되었다. Caffe는 2014년 UC Berkeley에서 공개되었으며, C, C++, Python, MATLAB을 지원한다. TensorFlow는 2015년 구글에서 공개되었고, C++와 Python을 지원하며, 다중 CPU와 GPU를 사용할 수 있다. Torch는 Facebook과 뉴욕 대학교(NYU)에서 개발되었으며, 그 후속 버전인 PyTorch는 Python 기반으로 개발되었다. 이 외에도 Theano, MXNet, CNTK와 같은 다양한 프레임워크가 있으며, Keras와 같은 상위 라이브러리도 존재한다. 이러한 프레임워크들은 DNN 연구자와 애플리케이션 설계자에게 편리한 도구를 제공할 뿐만 아니라, 고성능 DNN 계산 엔진을 설계하는 데도 매우 유용하다.
모델
다양한 웹사이트에서 여러 프레임워크용으로 사전 훈련된 DNN 모델을 다운로드할 수 있다. 동일한 DNN이라도 훈련 방식에 따라 정확도가 다를 수 있다. 예를 들어, AlexNet의 경우 훈련 방법에 따라 정확도가 1%~2% 차이 날 수 있다.
분류를 위한 데이터 세트
다양한 DNN 모델을 비교할 때, 작업의 난이도를 고려하는 것이 중요하다. MNIST는 손으로 쓴 숫자를 분류하는 데이터 세트로, 28 × 28 픽셀의 그레이스케일 이미지와 10개의 클래스로 구성되어 있다. CIFAR-10은 32 × 32 픽셀의 컬러 이미지와 10개의 클래스로 이루어져 있으며, 2009년에 공개되었다. ImageNet은 256 × 256 픽셀의 컬러 이미지를 포함하며, 1000개의 클래스를 가지고 있다. MNIST는 비교적 간단한 데이터 세트인 반면, ImageNet은 더 많은 클래스와 복잡한 구조를 가지고 있어 더 어려운 작업에 해당한다.
기타 작업을 위한 데이터 세트
최신 DNN의 정확도가 향상됨에 따라, ImageNet Challenge는 단일 객체 위치 지정 및 객체 탐지와 같은 더 어려운 작업에 초점을 맞추기 시작했다. 단일 객체 위치 지정의 경우, 대상 객체를 위치 지정하고 1000개의 클래스 중 하나로 분류해야 한다. 객체 탐지의 경우, 이미지의 모든 객체를 위치 지정하고 200개의 클래스 중 하나로 분류해야 한다. PASCAL VOC는 객체 탐지를 위한 데이터 세트로, 20개의 클래스를 나타내는 11,000개의 이미지를 포함한다. MS COCO는 객체 탐지, 분할 및 컨텍스트 인식을 위한 데이터 세트로, 91개의 객체 카테고리에 328,000개의 이미지를 포함하고 있다.
최근에는 더 큰 규모의 데이터 세트도 제공되고 있다. 구글의 Open Images 데이터 세트는 6,000개의 카테고리를 포함한 900만 개 이상의 이미지를 제공한다. YouTube 데이터 세트는 4800개의 클래스를 포함한 800만 개의 비디오를 제공한다. 이러한 대규모 데이터 세트는 DNN 연구와 효율성 탐색에 중요한 자원이 될 것이다.
결론적으로, 더 큰 데이터 세트와 새로운 도메인을 위한 데이터 세트는 향후 DNN 엔진의 효율성을 평가하고 탐색하는 데 중요한 역할을 한다.
5. Hardware for DNN Processing
DNN의 인기로 인해, 많은 하드웨어 플랫폼이 DNN 처리에 특화된 기능을 갖추고 있다. MAC 연산은 CONV층과 FC층에서 많은 양의 연산이 필요하다. 따라서, 이때 여러 아키텍처를 통해 병렬화함으로써 효율적인 처리를 가능하게 하는 것이 중요하다.
이 섹션에서는 정확도에 영향을 미치지 않고 다양한 플랫폼에서 효율적인 처리를 위한 다양한 설계 전략을 논의하며, temporal architecture와 spatial architecture에 대한 개념을 설명한다.
A. temporal architecture - CPU와 GPU의 커널 계산 가속화
temporal architecture은 CPU와 GPU에서 사용되는 것으로, SIMD와 SIMT의 병렬화를 통해 성능을 높인다. 이는 많은 ALU를 중앙 집중식 제어를 하는 방식이다. 단, 데이터 접근을 메모리를 통해서만 가능하며, ALU간 직접 상호작용할 수 없다.

- CPU와 GPU는 SIMD(단일 명령어, 다중 데이터)나 SIMT(단일 명령어, 다중 스레드)와 같은 병렬화 기법을 사용하여 병렬로 곱셈-누산(MAC) 연산 수행
- 모든 산술 논리 장치(ALU)는 동일한 제어 및 메모리(레지스터 파일)를 공유
<Convolution과 Matrix Mult 비교>
Convolution 레이어의 형태를 토플리츠 행렬을 사용하여 행렬 곱셈으로 매핑하는 방식이다. 입력 특징 맵을 중복된 데이터를 포함하는 토플리츠 행렬로 변환하고, 출력 형태 역시 행렬값으로 얻어진다. 단, 입력 특징 맵에서 중복 데이터가 존재하게 되면서 저장 효율이 떨어지거나 복잡한 메모리 접근 패턴을 초래할 수 있다.

- 효율성: 행렬 곱셈을 사용하면 병렬화가 쉬워지고, CPU와 GPU의 최적화 가능
- 통합: 합성곱 연산을 행렬 곱셈으로 변환하면 다양한 연산을 통합하여 처리할 수 있음
B. Energy - Efficient Dataflow for Accelerators
spatial architecture는 dataflow를 이용한 프로세싱 방법으로, ALU간 데이터를 서로 전달할 수 있는 구조이다. CNN model의 inception module, shortcut module등과 같은 다양한 방법을 사용하여 더 높은 정확성과 연산량을 줄이려고 하였다. 그러나, ResNet의 MAC의 개수를 보면 필요로 하는 연산량이 매-우 많다. 이런 연산을 처리하기 위해서는 많은 자원이 필요하고, 좋은 자원이 있어도 에너지 소모량도 방대하며 실행되는데 걸리는 시간도 오래걸린다. 이런 문제들을 줄이기 위한 방법에 대해서 알아본다.
<Spatial Architecture>
data reuser를 최대한 사용하기 위해 PE(Processing Element)를 사용하여 연산하는 부분을 구성한다.
- PE = MAC연산을 수행하는 연산자(ALU) + 재사용할 data를 저장해두는 local memory
- Spatial 아키텍처의 경우 매번 data를 register file에서 가져올 필요 없이 PE에서 사용한 data를 위 혹은 아래 PE로 넘겨줘서 다음 PE에서 data를 바로 사용할 수 있도록 연산, 또한 해당 PE를 거치는 여러 data가 local memory에 저장된 같은 값을 매번 사용하여 연산할 수 있음

이때, 로컬 메모리에 어떤 값을 저장하느냐에 따라 여러 종류로 나눌 수 있다.
(a) weight stationary (b) output stationary (c) no local reuse

(a) weight stationary
register file에서 weight를 가져오는 것을 최소화함으로써 weight를 읽을 때의 에너지 소모를 최소화하도록 설계된 구조. local memory에 weight값을 미리 DRAM에서 가져와서 저장해놓고 global buffer로부터 input값과 부분합을 받아서 해당 input값과 고정된 weight값이 계산되어 global buffer로 계산한 부분합을 저장
(b) output stationary
부분합을 읽고 쓸때의 에너지 소모를 최소화하도록 설계된 구조. register file에 저장된 같은 output activation에 대한 값을 합치게 해줌. 시스템 수준에서는 글로벌 버퍼가 입력 활성화를 스트리밍하고 PE 배열에 가중치를 브로드캐스트를 진행함
(c) no local reuse
모든 PE에 local memory와 control unit을 포함시켰을때 발생하는 비용때문에, reuse를 하지 않는 구조. PE에서 local memory를 두지 않. 당연히 data 재사용을 하지 않으므로 에너지 소모율은 가장 높음